1.先上图
直接看图

2.详说过程
2.1 DNS域名解析
- 在浏览器DNS缓存中搜索
- 在操作系统DNS缓存中搜索
- 读取系统hosts文件,查找其中是否有对应的ip
- 向本地配置的首选DNS服务器发起域名解析请求
2.2 建立TCP连接
为了准确地传输数据,TCP协议采用了三次握手策略。发送端首先发送一个带SYN(synchronize)标志的数据包给接收方,接收方收到后,回传一个带有SYN/ACK(acknowledegment)标志的数据包以示传达确认信息。最后发送方再回传一个带ACK标志的数据包,代表握手结束。在这过程中若出现问题中断,TCP会再次发送相同的数据包。
TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
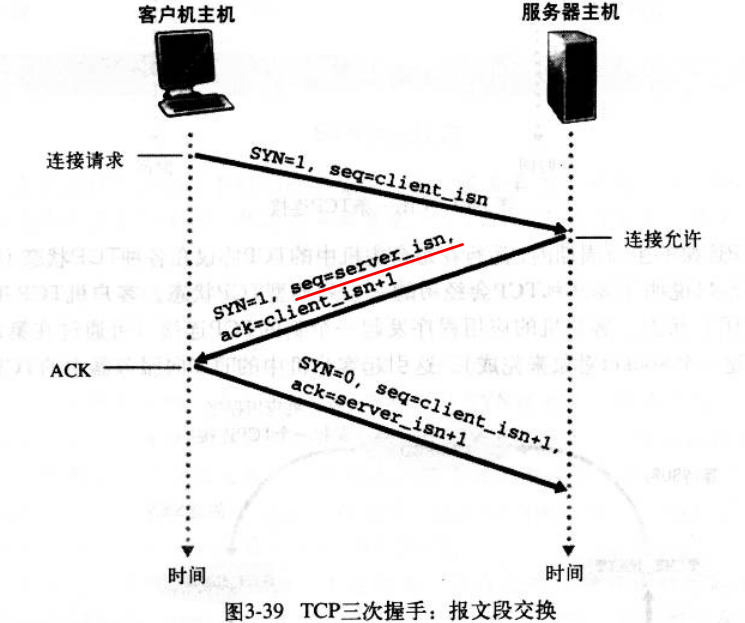
为什么要三次握手
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。在另一部经典的《计算机网络》一书中讲“三次握手”的目的是为了解决“网络中存在延迟的重复分组”的问题。
在谢希仁著《计算机网络》书中同时举了一个例子,如下:
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
中断连接端可以是Client端,也可以是Server端
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说”我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,”告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,”告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,”就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“Server端收到ACK后,”就知道可以断开连接了”。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
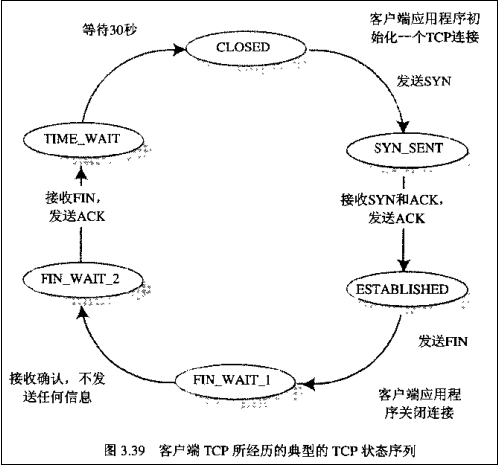

【注意】 在TIME_WAIT状态中,如果TCP client端最后一次发送的ACK丢失了,它将重新发送。TIME_WAIT状态中所需要的时间是依赖于实现方法的。典型的值为30秒、1分钟和2分钟。等待之后连接正式关闭,并且所有的资源(包括端口号)都被释放。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
2.3 发起HTTP请求
请求方法:
- GET:获取资源
- POST:传输实体主体
- HEAD:获取报文首部
- PUT:传输文件
- DELETE:删除文件
- OPTIONS:询问支持的方法
- TRACE:追踪路径
请求报文:

2.4 接受响应结果
状态码:
- 1**:信息性状态码
- 2**:成功状态码
200:OK 请求正常处理
204:No Content请求处理成功,但没有资源可返回
206:Partial Content对资源的某一部分的请求 - 3**:重定向状态码
301:Moved Permanently 永久重定向
302:Found 临时性重定向
304:Not Modified 缓存中读取 - 4**:客户端错误状态码
400:Bad Request 请求报文中存在语法错误
401:Unauthorized需要有通过Http认证的认证信息
403:Forbidden访问被拒绝
404:Not Found无法找到请求资源 - 5**:服务器错误状态码
500:Internal Server Error 服务器端在执行时发生错误
503:Service Unavailable 服务器处于超负载或者正在进行停机维护
响应报文:

2.5 浏览器解析html
浏览器按顺序解析html文件,构建DOM树,在解析到外部的css和js文件时,向服务器发起请求下载资源,若是下载css文件,则解析器会在下载的同时继续解析后面的html来构建DOM树,则在下载js文件和执行它时,解析器会停止对html的解析。这便出现了js阻塞问题。
预加载器:
当浏览器被脚本文件阻塞时,预加载器(一个轻量级的解析器)会继续解析后面的html,寻找需要下载的资源。如果发现有需要下载的资源,预加载器在开始接收这些资源。预加载器只能检索HTML标签中的URL,无法检测到使用脚本添加的URL,这些资源要等脚本代码执行时才会获取。
注: 预解析并不改变Dom树,它将这个工作留给主解析过程
浏览器解析css,形成CSSOM树,当DOM树构建完成后,浏览器引擎通过DOM树和CSSOM树构造出渲染树。渲染树中包含可视节点的样式信息(不可见节点将不会被添加到渲染树中,如:head元素和display值为none的元素)
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
2.6 浏览器布局渲染
- 布局:通过计算得到每个渲染对象在可视区域中的具体位置信息(大小和位置),这是一个递归的过程。
- 绘制:将计算好的每个像素点信息绘制在屏幕上
在页面显示的过程中会多次进行Reflow和Repaint操作,而Reflow的成本比Repaint的成本高得多的多。因为Repaint只是将某个部分进行重新绘制而不用改变页面的布局,如:改变了某个元素的背景颜色。而如果将元素的display属性由block改为none则需要Reflow。


